Our work spans five research thrusts, each tackling a different facet of how AI systems understand, anticipate, and act on dynamic video.

1. Strategic video intelligence for multi-agent worlds
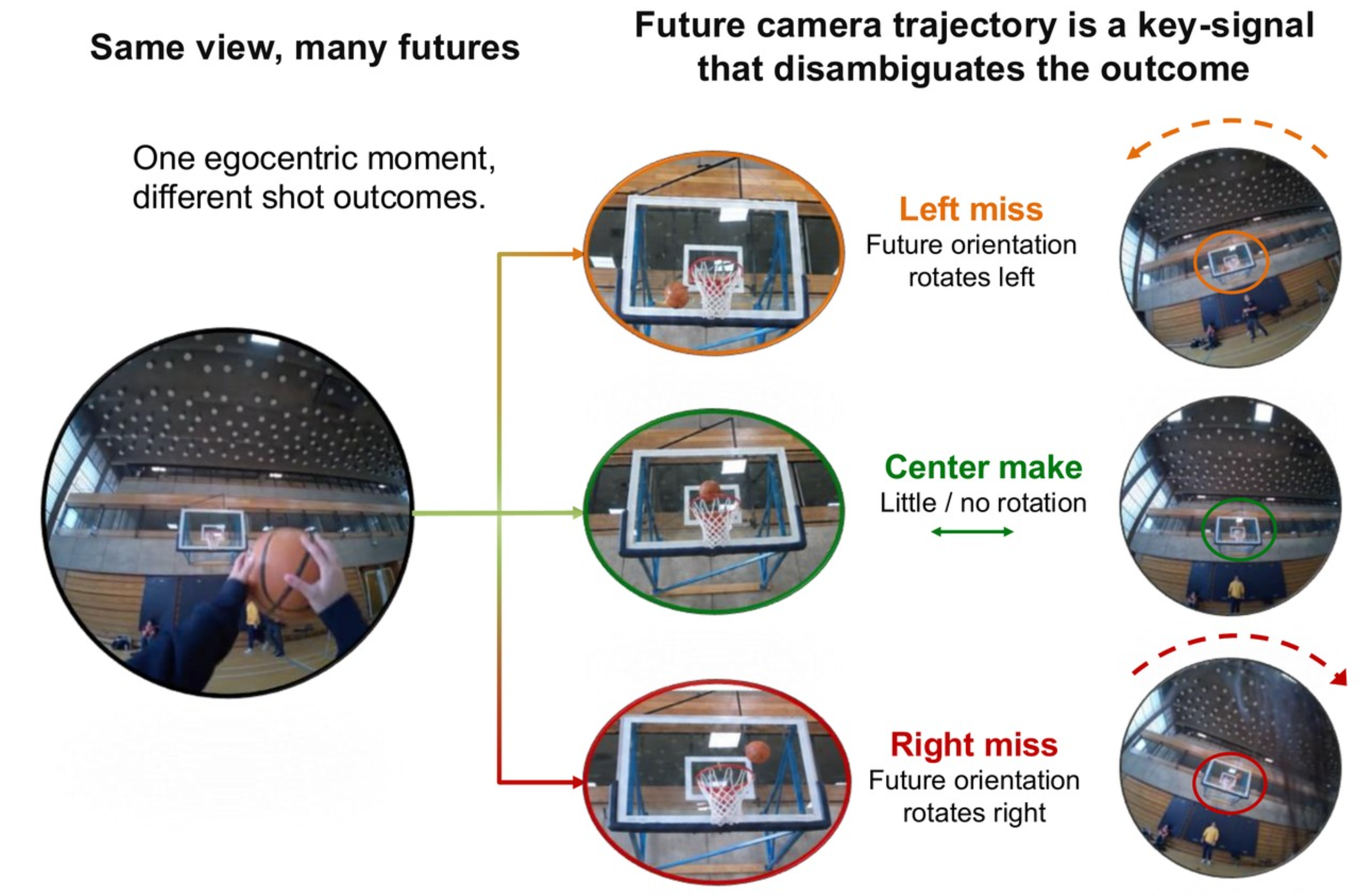
Most video understanding research evaluates perception in isolation. But agents deployed in the real world, including wearable assistants, robotic fleets, and coordinated teams, must also reason about cause and consequence, simulate alternative futures, and plan under uncertainty. We build benchmarks and models for the full perception-to-agency stack in dynamic multi-agent settings, using team sports as a natural microworld: rich and visually complex, with unambiguous outcomes and verifiable strategic ground truth. Our work exposes a substantial capability cliff in current systems: state-of-the-art models perceive multi-agent scenes well but fail at causal reasoning, strategic simulation, and agentic synthesis over the same evidence.
2. Egocentric perception, anticipation, and planning
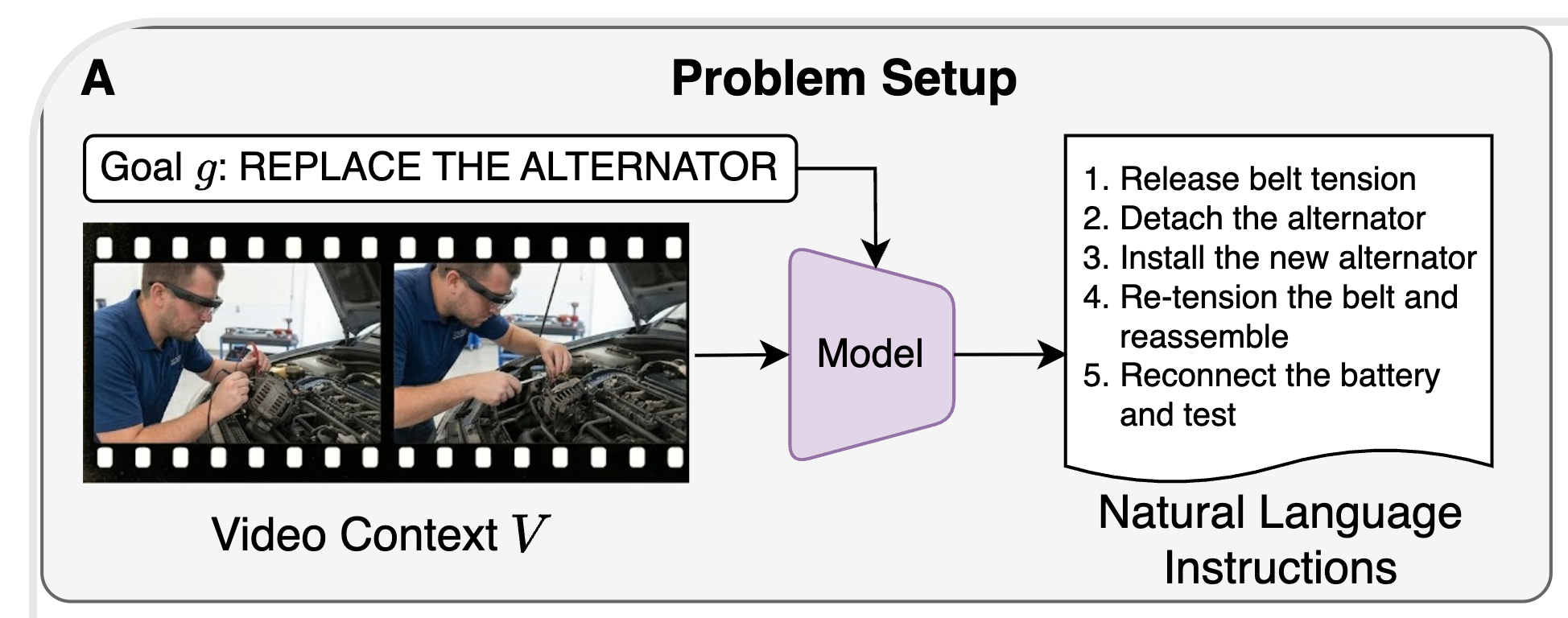
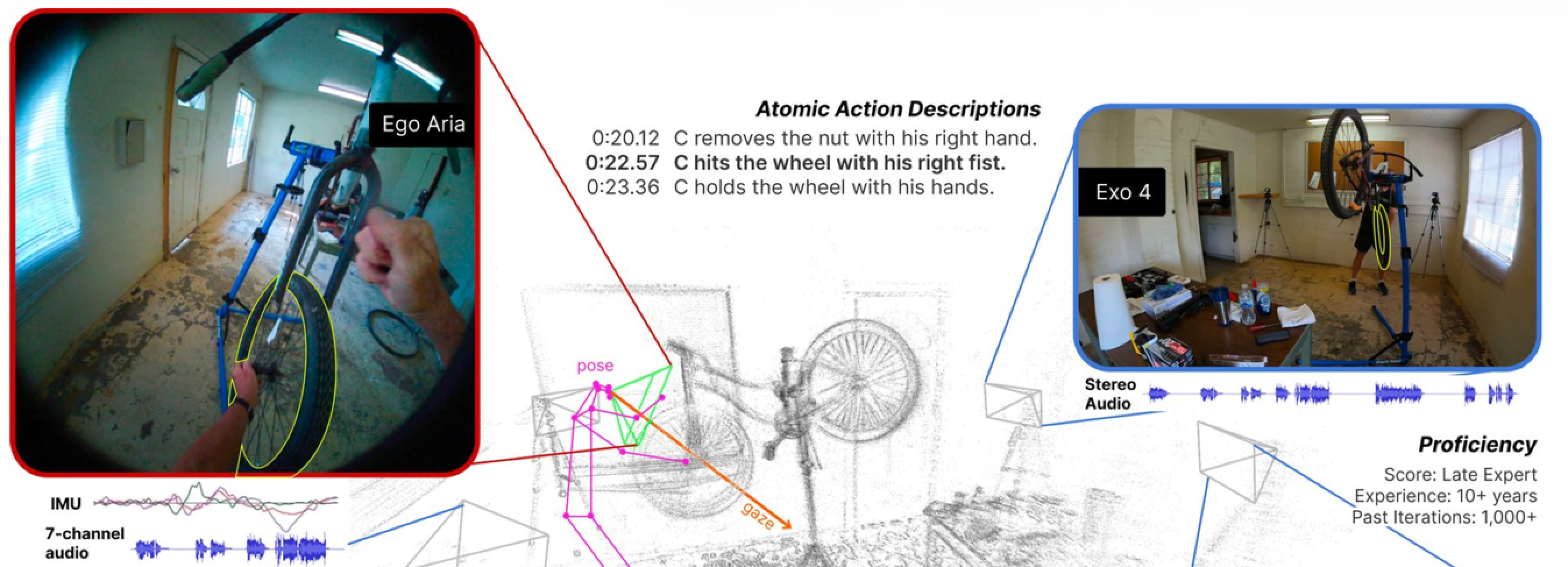
Many of the most important physical AI applications, including wearable assistants, AR guidance systems, and robots operating alongside humans, perceive the world from a first-person perspective. Egocentric video has distinctive properties that make it information-rich yet poorly served by methods designed for third-person video: continuous long-duration streams, head motion encoding visual attention, and hand-object interactions at close range. We develop benchmarks, data, and models for understanding skilled human activity from this perspective, and for systems that go beyond classifying what is happening now toward anticipating what will happen next and planning multi-step procedures.
Recent work
- How You Move Tells What You'll Do: Trajectory-Conditioned Egocentric Prediction..
- Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives (CVPR 2024).
- Ego4D Goal-Step: Toward Hierarchical Understanding of Procedural Activities (NeurIPS 2023).
3. Learning from video at scale, without manual labels
Clean labeled video datasets are small and narrow. The web offers orders of magnitude more video content, often paired with noisy speech transcripts or external articles, sometimes with no annotation at all. This abundance resists direct supervision. Narrations are temporally misaligned with the actions they describe. Speech captures actions only loosely. Step boundaries are not annotated, and many tasks lack paired text entirely.
We develop methods that turn this raw abundance into a useful training signal. Some of our work aligns instructional articles with how-to videos to discover step structure, or grounds procedural steps through correspondences between video, narration, and external knowledge. Other directions mine cross-video supervision for fine-grained comparison, treat noisy corpora as verifiers of generated plans rather than label sources, or train pairs of self-evolving agents that bootstrap their own supervision from raw unlabeled video. The resulting models generalize across domains and match or surpass fully supervised baselines while requiring no human annotation.
Recent work
- RECIPE: Procedural Planning via Grounding in Instructional Video.
- EvoGround: Self-Evolving Video Agents for Video Temporal Grounding.
- HT-Step: Aligning Instructional Articles with How-To Videos (NeurIPS 2023).
- Learning to Ground Instructional Articles in Videos through Narrations (ICCV 2023).
- Step Differences in Instructional Video (CVPR 2024).

4. Long-form video understanding and causal reasoning
Real-world activity unfolds over minutes to hours, far beyond the short clips most video models handle. We develop architectures that compress long video streams into compact memory representations supporting efficient question-answering, and we study causal and multi-hop reasoning across temporal spans where chain-of-thought approaches break down. Our BIMBA model adapts selective-scan mechanisms to video, winning the EgoSchema Challenge at CVPR 2025; our ViTED model produces visual-symbolic evidence justifying its answers without temporal annotations.
Recent work
- BIMBA: Selective-Scan Compression for Long-Range Video Question Answering (CVPR 2025).
- ViTED: Video Temporal Evidence Distillation (CVPR 2025).
5. Foundations: data engines for video understanding
Underlying all of the above is the challenge of producing the fine-grained video annotations that train strong models. We build data engines that use vision-language models to temporally segment video and auto-generate question-answer pairs, with active learning targeting human verification at low-confidence points. This pipeline produced PLM-FGQA, the largest manually-labeled video question-answering dataset, which trains an open-source VLM that outperforms proprietary industry models on video understanding benchmarks.
Recent work
- PerceptionLM: Open-Access Data and Models for Detailed Visual Understanding (NeurIPS 2025).
- Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives (CVPR 2024).
For the full list of papers and code, see publications.